
In the last few months I’ve had the opportunity to revisit all of the decisions I made in 2007 and 2008 about how I transcribe my manuscripts. In this post I’ll talk about why I make full transcriptions in the first place, the system I devised six years ago, my migration to T-PEN, and a Python tool I’ve written to convert my T-PEN data into usable TEI XML.
Transcription vs. collation
When I make a critical edition of a text, I start with a full transcription of the manuscripts that I’m working with, fairly secure in the knowledge that I’ll be able to get the computer to do 99% of the work of collating them. There are plenty of textual scholars out there who will regard me as crazy for this. Transcribing a manuscript is a lot of work, after all, and wouldn’t it just be faster to do the collation myself in the first place? But my instinctive answer has always been no, and I’ll begin this post by trying to explain why.
When I transcribe my manuscripts, I’m working with a plain-text copy of the text that was made via OCR of the most recent (in this case, 117-year-old) printed edition. So in a sense the transcription I do is itself a collation against that edition text – I make a file copy of the text and begin to follow along it with reference to the printed edition, and wherever the manuscript varies, I make a change in the file copy. At the same time, I can add notation for where line breaks, page divisions, scribal corrections, chapter or section markings, catchwords, colored ink, etc. all occur in the manuscript. By the end of this process, which is in principle no different from what I would be doing if I were constructing a manual collation, I have a reasonably faithful transcription of the manuscript I started with.
But there are two things about this process that make it, in my view, simpler and faster than constructing that collation. The first is the act I’m performing on the computer, and the second is the number of simultaneous comparisons and decisions I have to make at each point in the process. When I transcribe I’m correcting a single text copy, typing in my changes and moving on, in a lines-and-paragraphs format that is pretty similar to the text I’m looking at. The physical process is fairly similar to copy-editing. If I were collating, I would be working – most probably – in a spreadsheet program, trying to follow the base text word-by-word in a single column and the manuscript in its paragraphs, which are two very different shapes for text. Wherever the text diverged, I would first have to make a decision about whether to record it (that costs mental energy), then have to locate the correct cell to record the difference (that costs both mental energy and time spent switching from keyboard to mouse entry), and then deciding exactly how to record the change in the appropriate cell (switching back from mouse to keyboard), thinking also about how it coordinates with any parallel variants in manuscripts already collated. Quite frankly, when I think about doing work like that I not only get a headache, but my tendinitis-prone hands also start aching in sympathy.
Making a transcription
So for my own editorial work I am committed to the path of making transcriptions now and comparing them later. I was introduced to the TEI for this purpose many years ago, and conceptually it suits my transcription needs. XML, however, is not a great format for writing out by hand for anyone, and if I were to try, the transcription process would quickly become as slow and painful as I have just described the process of manual collation as being.
As part of my Ph.D. work I solved this problem by creating a sort of markup pidgin, in which I used single-character symbols to represent the XML tags I wanted to use. The result was that, when I had a manuscript line like this one:

whose plaintext transcription is this:
Եւ յայնժամ սուրբ հայրապետն պետրոս և իշխանքն ելին առ աշոտ. և
and whose XML might look something like this:
<lb/><hi rend="red">Ե</hi>ւ յայնժ<ex>ա</ex>մ ս<ex>ուր</ex>բ
հ<ex>ա</ex>յր<ex>ա</ex>պ<ex>ե</ex>տն պետրոս և
իշխ<ex>ա</ex>նքն ելին առ աշոտ. և
I typed this into my text editor
*(red)Ե*ւ յայնժ\ա\մ ս\ուր\բ հ\ա\յր\ա\պ\ե\տն պետրոս և իշխ\ա\նքն
ելին առ աշոտ. և
and let a script do the work of turning that into full-fledged XML. The system was effective, and had the advantage that the text was rather easier to compare with the manuscript image than full XML would be, but it was not particularly user-friendly – I had to have all my symbols and their tag mappings memorized, I had to make sure that my symbols were well-balanced, and I often ran into situations (e.g. any tag that spanned more than one line) where my script was not quite able to produce the right result. Still, it worked well enough, I know at least one person who was actually willing to use it for her own work, and I even wrote an online tool to do the conversion and highlight any probable errors that could be detected.
My current solution
Last October I was at a collation workshop in Münster, where I saw a presentation by Alison Walker about T-PEN, an online tool for manuscript transcription. Now I’ve known about T-PEN since 2010, and had done a tiny bit of experimental work with it when it was released, but had not really thought much about it since. During that meeting I fired up T-PEN for the first time in years, really, and started working on some manuscript transcription, and actually it was kind of fun!
What T-PEN does is to take the manuscript images you have, find the individual lines of text, and then let you do the transcription line-by-line directly into the browser. The interface looks like this (click for a full-size version):
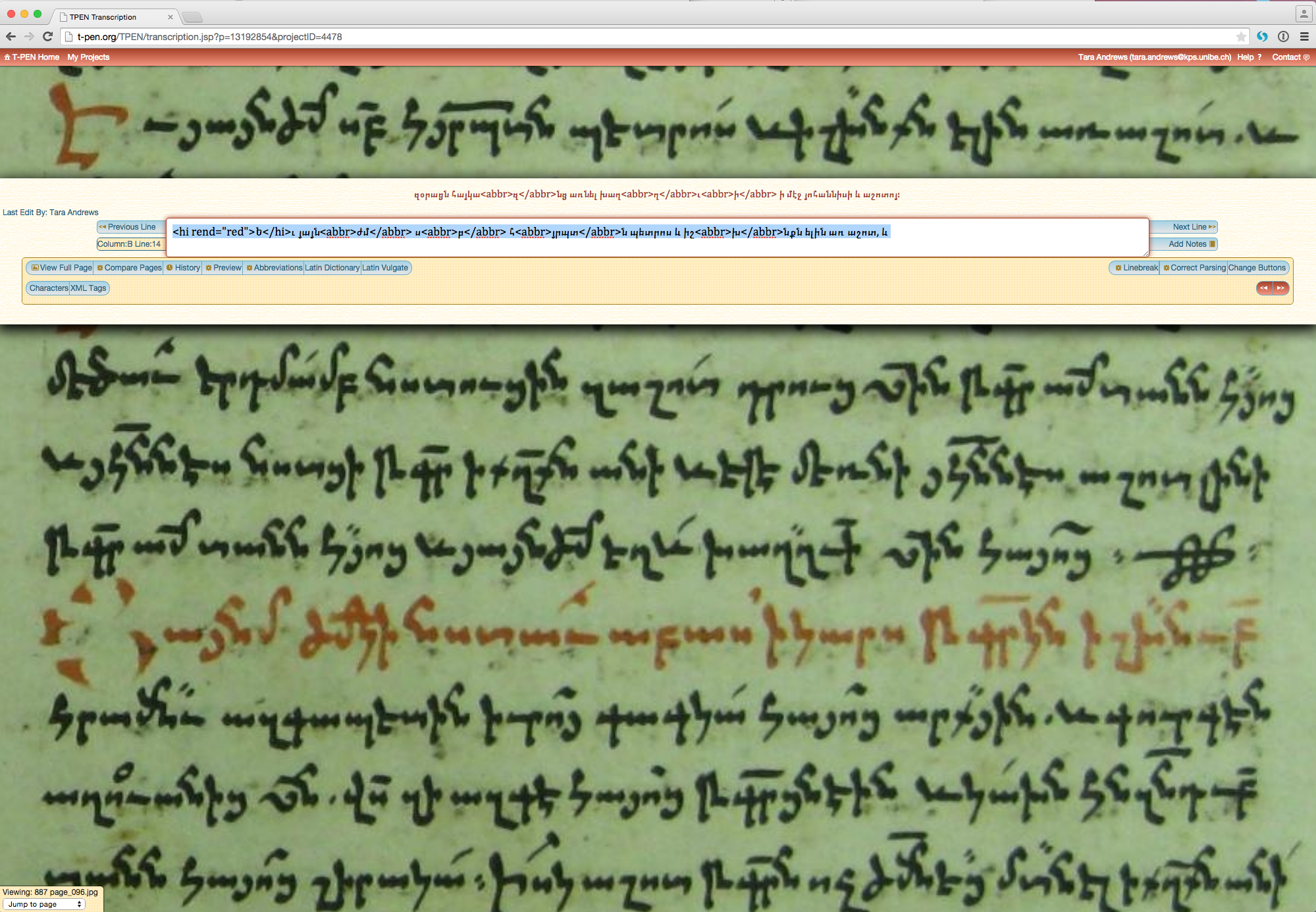
which makes it just about the ideal transcription environment from a user-interface perspective. You would have to try very hard to inadvertently skip a line; your eyes don’t have to travel very far to get between the manuscript image and the text rendition; when it’s finished, you have not only the text but also the information you need to link the text to the image for later presentation.
The line recognition is not perfect, in my experience, but it is often pretty good, and the user is free to correct the results. It is pretty important to have good images to work with – cropped to include only the pages themselves, rotated and perhaps de-skewed so that the lines are straight, and with good contrast. I have had the good fortune this term to have an intern, and we have been using ImageMagick to do the manuscript image preparation as efficiently as we can. It may be possible to do this fully automatically – I think that OCR software like FineReader has similar functionality – but so far I have not looked seriously into the possibility.
T-PEN does not actively support TEI markup, or any other sort of markup. What it does offer is the ability to define buttons (accessible by clicking the ‘XML Tags’ button underneath the transcription box) that will apply a certain tag to any portion of text you choose. I have defined the TEI tags I use most frequently in my transcriptions, and using them is fairly straightforward.
Getting data back out
There are a few listed options for exporting a transcription done in T-PEN. I found that none of them were quite satisfactory for my purpose, which was to turn the transcription I’d made automatically into TEI XML, so that I can do other things with it. One of the developers on the project, Patrick Cuba, who has been very helpful in answering all the queries I’ve had so far, pointed out to me the (so far undocumented) possibility of downloading the raw transcription data – stored on their system using the Shared Canvas standard – in JSON format. Once I had that it was the work of a few hours to write a Python module that will convert the JSON transcription data into valid TEI XML, and will also tokenize valid TEI XML for use with a collation tool such as CollateX.
The tpen2tei module isn’t quite in a state where I’m willing to release it to PyPI. For starters, most of the tests are still stubs; also, I suspect that I should be using an event-based parser for the word tokenization, rather than the DOM parser I’m using now. Still, it’s on Github and there for the using, so if it is the sort of tool you think you might need, go wild.
Desiderata
There are a few things that T-PEN does not currently do, that I wish it did. The first is quite straightforward: on the website it is possible to enter some metadata about the manuscript being transcribed (library information, year of production, etc.), but this metadata doesn’t make it back into the Shared Canvas JSON. It would be nice if I had a way to get all the information about my manuscript in one place.
The second is also reasonably simple: I would like to be able to define an XML button that is a milestone element. Currently the interface assumes that XML elements will have some text inside them, so the button will insert a <tag> and a </tag> but never a <tag/>. This isn’t hard to patch up manually – I just close the tag myself – but from a usability perspective it would be really handy.
The third has to do with resource limits currently imposed by T-PEN: although there doesn’t seem to be a limit to the number of manuscripts you upload, each manuscript can contain only up to 200MB of image files. If your manuscript is bigger, you will have to split it into multiple projects and combine the transcriptions after the fact. Relatedly, you cannot add new images to an existing manuscript, even if you’re under the 200MB limit. I’m told that an upcoming version of T-PEN will address at least this second issue.
The other two things I miss in T-PEN have to do with the linking between page area and text flow, and aren’t quite so simple to solve. Occasionally a manuscript has a block of text written in the margin; sometimes the block is written sideways. There is currently no good mechanism for dealing with blocks of text with weird orientations; the interface assumes that all zones should be interpreted right-side-up. Relatedly, T-PEN makes the assumption (when it is called upon to make any assumption at all) that text blocks should be interpreted from top left to bottom right. It would be nice to have a way to define a default – perhaps I’m transcribing a Syriac manuscript? – and to specify a text flow in a situation that doesn’t match the default. (Of course, there are also situations where it isn’t really logical or correct to interpret the text as a single sequence! That is part of what makes the problem interesting.)
Conclusion
If someone who is starting an edition project today asks me for advice on transcription, I would have little reservation in pointing them to T-PEN. The only exception I would make is for anyone working on a genetic or documentary edition of authors’ drafts or the like. The T-PEN interface does assume that the documents being transcribed are relatively clean manuscripts without a lot of editorial scribbling. Apart from that caveat, though, it is really the best tool for the task that I have seen. It has a great user interface for the task, it is an open source tool, its developers have been unfailingly helpful, and it provides a way to get out just about all of the data you put into it. In order to turn that data into XML, you may have to learn a little Python first, but I hope that the module I have written will give someone else a head start on that front too!